Legacy: Gestural Computational Model
Introduction to Articulatory Phonology and the Gestural Model
Traditionally, human speech has been seen as having two structures, one considered physical, and the other cognitive, where the relation between the two structures is generally not an intrinsic part of either description. From this perspective, a complete picture requires ‘translating’ between the intrinsically incommensurate domains (as argued by Fowler, Rubin, Remez, & Turvey, 1980). Articulatory Phonology ( Browman & Goldstein, 1986; 1989; 1990a,b; 1992) begins with the very different assumption that these apparently different domains are, in fact, the low and high dimensional descriptions of a single (complex) system. Crucial to this approach is identification of phonological units with dynamically specified units of articulatory action, called gestures. Thus, an utterance is described as an act that can be decomposed into a small number of primitive units (a low dimensional description), in a particular spatio-temporal configuration. The same description also provides an intrinsic specification of the high dimensional properties of the act (its various mechanical and bio-mechanical consequences).
Gestures and Task Dynamics
Articulatory phonology takes seriously the view that the units of speech production are actions, and therefore that (1) they are dynamic, not static. Further, since articulatory phonology considers phonological functions such as contrast to be low-dimensional, macroscopic descriptions of such actions, the basic units are (2) not neutral between articulation and acoustics, but rather are articulatory in nature. Thus, in articulatory phonology, the basic phonological unit is the articulatory gesture, which is defined as a dynamical system specified with a characteristic set of parameter values (see Saltzman, in 1998). Finally, because the tasks are distributed across the various articulator sets of the vocal tract (the lips, tongue, glottis, velum, etc.), an utterance is modeled as an ensemble, or constellation, of a small number of (3) potentially overlapping gestural units.
Phonological contrast among utterances can be defined in terms of these gestural constellations. Thus, these structures can capture the low-dimensional properties of utterances. In addition, because each gesture is defined as a dynamical system, no rules of implementation are required to characterize the high-dimensional properties of the utterance. A time-varying pattern of articulator motion (and its resulting acoustic consequences) is lawfully entailed by the dynamical systems themselves–they are self-implementing. Moreover, these time-varying patterns automatically display the property of context dependence (which is ubiquitous in the high dimensional description of speech) even though the gestures are defined in a context-independent fashion. The nature of the articulatory dimensions along which the individual dynamical units are defined allows this context dependence to emerge lawfully.
The articulatory phonology approach was incorporated into a computational system developed at Haskins Laboratories (Browman, Goldstein, Kelso, Rubin, & Saltzman, 1984; Saltzman, 1986; Saltzman & Munhall, 1989; Browman & Goldstein, 1990a,c). In this system, illustrated in Figure 1, utterances are organized ensembles (or constellations) of units of articulatory action called gestures. Each gesture is modeled as a dynamical system that characterizes the formation (and release) of a local constriction within the vocal tract (the gesture’s functional goal or `task’). For example, the word “ban” begins with a gesture whose task is lip closure. The formation of this constriction entails a change in the distance between upper and lower lips (or Lip Aperture) over time. This change is modeled using a second order system (a `point attractor,’ Abraham and Shaw, 1982), specified with particular values for the equilibrium position and stiffness parameters. (Damping is, for the most part, assumed to be critical, so that the system approaches its equilibrium position and doesn’t overshoot it). During the activation interval for this gesture, the equilibrium position for Lip Aperture is set to the goal value for lip closure; the stiffness setting, combined with the damping, determines the amount of time it will take for the system to get close to the goal of lip closure.

Figure 1.
The set of task or tract variables implemented in the computational model are listed at the top left of Figure 2, and the sagittal vocal tract shape below illustrates their geometric definitions. This set of tract variables is hypothesized to be sufficient for characterizing most of the gestures of English (exceptions involve the details of characteristic shaping of constrictions, see Browman & Goldstein, 1989). For oral gestures, two paired tract variable regimes are specified, one controlling the constriction degree of a particular structure, the other its constriction location (a tract variable regime consists of a set of values for the dynamic parameters of stiffness, equilibrium position, and damping ratio). Thus, the specification for an oral gesture includes an equilibrium position, or goal, for each of two tract variables, as well as a stiffness (which is currently yoked across the two tract variables). Each functional goal for a gesture is achieved by the coordinated action of a set of articulators, that is, a coordinative structure (Fowler et al., 1980; Kelso, Saltzman & Tuller, 1986; Saltzman, 1986; Turvey, 1977); the sets of articulators used for each of the tract variables are shown on the top right of Figure 2, with the articulators indicated on the outline of the vocal tract model below. Note that the same articulators are shared by both of the paired oral tract variables, so that altogether there are five distinct articulator sets, or coordinative structure types, in the system.
In the computational system the articulators are those of a vocal tract model, the Haskins articulatory synthesis model, ASY (Rubin, Baer, & Mermelstein, 1981) that can generate speech waveforms from a specification of the positions of individual articulators. When a dynamical system (or pair of them) corresponding to a particular gesture is imposed on the vocal tract, the task-dynamic model (Saltzman, 1986; Saltzman & Kelso, 1987; Saltzman & Munhall, 1989) calculates the time-varying trajectories of the individual articulators comprising that coordinative structure, based on the information about values of the dynamic parameters, etc, contained in its input. These articulator trajectories are input to the vocal tract model, which then calculates the resulting global vocal tract shape, area function, transfer function, and speech waveform (see Figure 1).
Defining gestures dynamically can provide a principled link between macroscopic and microscopic properties of speech. To illustrate some of the ways in which this is true, consider the example of lip closure. The values of the dynamic parameters associated with a lip closure gesture are macroscopic properties that define it as a phonological unit and allow it to contrast with other gestures such as the narrowing gesture for [w]. These values are definitional, and remain invariant as long as the gesture is active. At the same time, however, the gesture intrinsically specifies the (microscopic) patterns of continuous change that the lips can exhibit over time. These changes emerge as the lawful consequences of the dynamical system, its parameters, and the initial conditions. Thus, dynamically defined gestures provide a lawful link between macroscopic and microscopic properties.
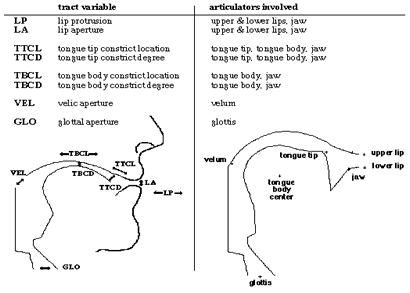
Figure 2.
The physical properties of a given phonological unit vary considerably depending on its context (e.g., Kent & Minifie, 1977; Liberman, Cooper, Shankweiler, & Studdert-Kennedy, 1967; Öhman, 1966). Much of this context dependence emerges lawfully from the use of task dynamics. An example of this kind of context dependence in lip closure gestures can be seen in the fact that the three independent articulators that can contribute to closing the lips (upper lip, lower lip, and jaw) do so to different extents as a function of the vowel environment in which the lip closure is produced (Macchi, 1988; Sussman, MacNeilage, & Hanson, 1973). The value of lip aperture achieved, however, remains relatively invariant no matter what the vowel context. In the task-dynamic model, the articulator variation results automatically from the fact that the lip closure gesture is modeled as a coordinative structure that links the movements of the three articulators in achieving the lip closure task. The gesture is specified invariantly in terms of the tract variable of lip aperture, but the closing action is distributed across component articulators in a context-dependent way. For example, in an utterance like [ibi], the lip closure is produced concurrently with the tongue gesture for a high front vowel. This vowel gesture will tend to raise the jaw, and thus, less activity of the upper and lower lips will be required to effect the lip closure goal than in an utterance like [aba]. These microscopic variations emerge lawfully from the task dynamic specification of the gestures, combined with the fact of overlap (Kelso, Saltzman, & Tuller, 1986; Saltzman & Munhall, 1989).
Gestural Structures
During the act of talking, more than one gesture is activated, sometimes sequentially and sometimes in an overlapping fashion. Recurrent patterns of gestures are considered to be organized into gestural constellations. In the computational model (see Figure 1), the linguistic gestural model determines the relevant constellations for any arbitrary input utterance, including the phasing of the gestures. That is, a constellation of gestures is a set of gestures that are coordinated with one another by means of phasing, where for this purpose (and this purpose only), the dynamical regime for each gesture is treated as if it were a cycle of an undamped system with the same stiffness as the actual regime. In this way, any characteristic point in the motion of the system can be identified with a phase of this virtual cycle. For example, the movement onset of a gesture is at phase 0 degrees, while the achievement of the constriction goal (the point at which the critically damped system gets sufficiently close to the equilibrium position) occurs at phase 240 degrees. Pairs of gestures are coordinated by specifying the phases of the two gestures that are synchronous. For example, two gestures could be phased so that their movement onsets are synchronous (0 degrees phased to 0 degrees), or so that the movement onset of one is phased to the goal achievement of another (0 degrees phased to 240 degrees), etc. Generalizations that characterize some phase relations in the gestural constellations of English words are proposed in Browman and Goldstein (1990c). As is the case for the values of the dynamic parameters, values of the synchronized phases also appear to cluster in narrow ranges, with onset of movement (0 degrees) and achievement of goal (240 degrees) being the most common (Browman & Goldstein, 1990a).
An example of a gestural constellation (for the word “pawn” as pronounced with the back unrounded vowel characteristic of much of the U.S.) is shown in Figure 3a, which gives an idea of the kind of information contained in the gestural dictionary. Each row, or tier, shows the gestures that control the distinct articulator sets: velum, tongue tip, tongue body, lips, and glottis. The gestures are represented here by descriptors, each of which stands for a numerical equilibrium position value assigned to a tract variable. In the case of the oral gestures, there are two descriptors, one for each of the paired tract variables. For example, for the tongue tip gesture labeled {clo alv}, {clo} stands for -3.5 mm (negative value indicates compression of the surfaces), and {alv} stands for 56 degrees (where 90 degrees is vertical and would correspond to a midpalatal constriction). The association lines connect gestures that are phased with respect to one another. For example, the tongue tip {clo alv} gesture and the velum {wide} gesture (for nasalization) are phased such that the point indicating 0 degrees–onset of movement–of the tongue tip closure gesture is synchronized with the point indicating 240 degrees–achievement of goal–of the velic gesture.
Each gesture is assumed to be active for a fixed proportion of its virtual cycle (the proportion is different for consonant and vowel gestures). The linguistic gestural model uses this proportion, along with the stiffness of each gesture and the phase relations among the gestures, to calculate a gestural score that specifies the temporal activation intervals for each gesture in an utterance. One form of this gestural score for “pawn” is shown in Figure 3b, with the horizontal extent of each box indicating its activation interval, and the lines between boxes indicating which gesture is phased with respect to which other gesture(s), as before. Note that there is substantial overlap among the gestures. This kind of overlap can result in certain types of context dependence in the articulatory trajectories of the invariantly specified gestures. In addition, overlap can cause the kinds of acoustic variation that have been traditionally described as allophonic variation. For example in this case, note the substantial overlap between the velic lowering gesture (velum {wide}) and the gesture for the vowel (tongue body {narrow pharyngeal}). This will result in an interval of time during which the velo-pharyngeal port is open and the vocal tract is in position for the vowel–that is, a nasalized vowel. Traditionally, the fact of nasalization has been represented by a rule that changes an oral vowel into a nasalized one before a (final) nasal consonant. But viewed in terms of gestural constellations, this nasalization is just the lawful consequence of how the individual gestures are coordinated. The vowel gesture itself hasn’t changed in any way: it has the same specification in this word and in the word “pawed” (which is not nasalized).

Figure 3a.

Figure 3b.
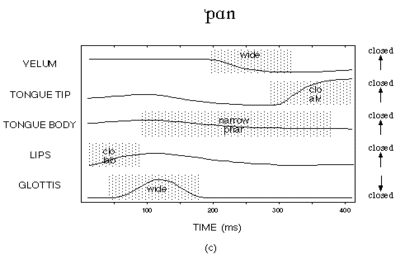
Figure 3c.
The parameter value specifications and activation intervals from the gestural score are input to the task dynamic model (Figure 1), which calculates the time-varying response of the tract variables and component articulators to the imposition of the dynamical regimes defined by the gestural score. Some of the time-varying responses are shown in Figure 3c, along with the same boxes indicating the activation intervals for the gestures. Note that the movement curves change over time even when a tract variable is not under the active control of some gesture. Such motion can be seen, for example, in the LIPS panel, after the end of the box for the lip closure gesture. This motion results from one or both of two sources. (1) When an articulator is not part of any active gesture, the articulator returns to a neutral position. In the example, the upper lip and the lower lip articulators both are returning to a neutral position after the end of the lip closure gesture. (2) One of the articulators linked to the inactive tract variable may also be linked to some active tract variable, and thus cause passive changes in the inactive tract variable. In the example, the jaw is part of the coordinative structure for the tongue body vowel gesture, as well as part of the coordinative structure for the lip closure gesture. Therefore, even after the lip closure gesture becomes inactive, the jaw is affected by the vowel gesture, and its lowering for the vowel causes the lower lip to also passively lower. In these ways, “uncontrolled” motions can be produced by the system, and this is crucial to some of experiments (on “targetless” vowels) in the current proposal.
The gestural constellations not only characterize the microscopic properties of the utterances, as discussed above, but systematic differences among the constellations also define the macroscopic property of phonological contrast in a language. Given the nature of gestural constellations, the possible ways in which they may differ from one another is, in fact, quite constrained. In other papers (e.g., Browman and Goldstein, 1986; 1989; 1992) we have begun to show that gestural structures are suitable for characterizing phonological functions such as contrast, and what the relation is between the view of phonological structure implicit in gestural constellations, and that found in other contemporary views of phonology (see also Clements, 1992 for a discussion of these relations). Here we simply give some examples of how the notion of contrast is defined in a system based on gestures, using the schematic gestural scores in Figure 4.

Figure 4, Part 1.

Figure 4, Part 2.
One way in which constellations may differ is in the presence vs. absence of a gesture. This kind of difference is illustrated by two pairs of subfigures in Figure 4: (4a) vs. (4b) and (4b) vs.(4d). (4a) “pan” differs from (4b) “ban” in having a glottis {wide} gesture (for voicelessness), while (4b) “ban” differs from (4d) “Ann” in having a labial closure gesture (for the initial consonant). Constellations may also differ in the particular tract variable/articulator set controlled by a gesture within the constellation, as illustrated by (4a) “pan” vs.(4c) “tan,” which differ in terms of whether it is the lips or tongue tip that perform the initial closure. A further way in which constellations may differ is illustrated by comparing (4e) “sad” to (4f) “shad,” in which the value of the constriction location tract variable for the initial tongue tip constriction is the only difference between the two utterances. Finally, two constellations may contain the same gestures and differ simply in how they are coordinated, as can be seen in (4g) “dab” vs. (4h) “bad.”
For more information about the Gestural Computational Model, and to download a software implementation, please visit our TADA page.
References
Abraham, R. H., and Shaw, C. D. (1982). Dynamics–The geometry of behavior. Santa Cruz, CA: Aerial Press.
Browman, C. P., and Goldstein, L. (1986). Towards an articulatory phonology. Phonology Yearbook, 3, 219-252. (PDF)
Browman, C. P., and Goldstein, L. (1989). Articulatory gestures as phonological units. Phonology, 6, 201-251.
Browman, C. P., and Goldstein, L. (1990a). Gestural specification using dynamically-defined articulatory structures. Journal of Phonetics, 18, 299-320.
Browman, C. P., and Goldstein, L. (1990b). Representation and reality: Physical systems and phonological structure. Journal of Phonetics, 18, 411-424.
Browman, C. P., and Goldstein, L. (1990c). Tiers in articulatory phonology, with some implications for casual speech. In T. Kingston and M. E. Beckman (Eds.), Papers in Laboratory Phonology I: Between the Grammar and Physics of Speech (pp. 341-376). Cambridge University Press.
Browman, C. P., & Goldstein, L. (1992). Articulatory phonology: An overview. Phonetica, 49, 155-180. (PDF)
Browman, C. P., Goldstein, L., Kelso, J .A. S., Rubin, P., and Saltzman, E. (1984). Articulatory synthesis from underlying dynamics. Journal of the Acoustical Society, 75, S22-S23 (A).
Byrd, Dani, and Jelena Krivokapic. (2021). Cracking Prosody in Articulatory Phonology. Annual Review of Linguistics, 7:31–53. https://doi.org/10.1146/annurev-linguistics-030920-050033.
Clements, G. N. (1992). Phonological primes: Features or gestures? Phonetica, 49, 181-193.
Fowler, C. A., Rubin, P., Remez, R. E., and Turvey, M. T. (1980). Implications for speech production of a general theory of action. In B. Butterworth (Ed.), Language production. New York: Academic Press. (PDF)
Kelso, J. A. S., Saltzman, E. L., and Tuller, B. (1986). The dynamical perspective on speech production: data and theory. Journal of Phonetics, 14, 29-59.
Kent, R. D., and Minifie, F. D. (1977). Coarticulation in recent speech production models. Journal of Phonetics, 5, 115-133.
Liberman, A. M., Cooper, F. S., Shankweiler, D. P., and Studdert-Kennedy, M. (1967). Perception of the speech code. Psychological Review, 74, 431-461. (PDF)
Macchi, M. (1988). Labial articulation patterns associated with segmental features and syllable structure in English. Phonetica, 45, 109-121.
Öhman, S. E. G. (1966). Coarticulation in VCV utterances: Spectrographic measurements. Journal of the Acoustical Society, 39, 151-168.
Rubin, P. E., Baer, T., and Mermelstein, P. (1981) An articulatory synthesizer for perceptual research, Journal of the Acoustical Society, 70, 321-328. (PDF)
Saltzman, E. (1986). Task dynamic coordination of the speech articulators: A preliminary model. In H. Heuer and C. Fromm (Eds.), Experimental Brain Research Series 15 (pp. 129-144). New York: Springer-Verlag. (PDF)
Saltzman, E. (1998). Dynamics and coordinate systems in skilled sensorimotor activity. In Port, R. and Van Gelder, T. (Eds.), Mind as motion. Cambridge, MA: MIT Press.
Saltzman, E., and Kelso, J. A. S. (1987). Skilled actions: A task dynamic approach. Psychological Review, 94, 84-106. (PDF)
Saltzman, E. L., and Munhall, K. G. (1989) A dynamical approach to gestural patterning in speech production. Ecological Psychology, 1, 333-382. (PDF)
Sussman, H. M., MacNeilage, P. F., and Hanson, R. J. (1973). Labial and mandibular dynamics during the production of bilabial consonants: Preliminary observations. Journal of Speech and Hearing Research, 16, 397-420.
Turvey, M. T. (1977). Preliminaries to a theory of action with reference to vision. In R. Shaw and J. Bransford (Eds.), Perceiving, acting and knowing: Toward an ecological psychology. Hillsdale, NJ: LEA.
(See, also: Asilomar Workshop, Advancing Research in Phonology via Articulatory Phonology (ARP_AP), 12-14 July 2019.)